It struck me today; there is an easy way to describe MySQL’s Binary Log group commit improvements from MySQL 5.0-5.7 by using the example of a single ferry trying to ship passengers from point A to point B:
MySQL 5.0 Behaviour
In MySQL 5.0, the ferry will pick up the next passenger in line from point A, and transfer them to point B. The trip between A and B takes about 10 minutes return trip, so it’s possible that several new passengers will arrive while the ferry is in transit. That doesn’t matter; when the ferry arrives back at point A, it will only pick up the very next passenger in line.
MySQL 5.6 Behaviour
In MySQL 5.6, the ferry will pick up all passengers from the line at point A, and then transfer them to point B. Each time it returns to point A to pick up new passengers, it will collect everyone who is waiting and transfer them across to point B.
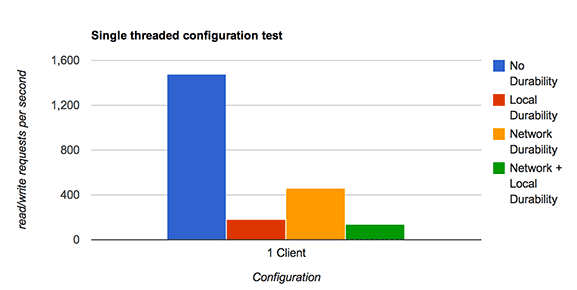
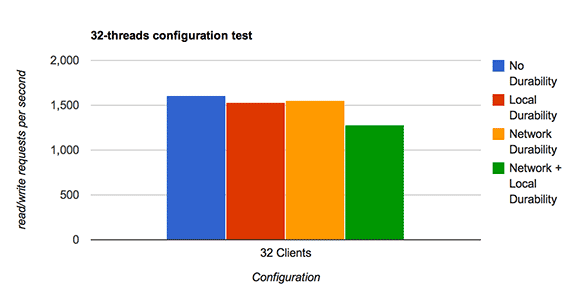
This is measurably better performance in real-life situations where many passengers tend to arrive while waiting for the ferry to arrive back at point A, and the trip between A and B tends to take some time. It is not so measurable in naive benchmarks that run in a single-thread.
There is no configuration necessary to enable group commit in 5.6. It works by default.
MySQL 5.7 Behaviour
MySQL 5.7 behaves similarly to 5.6 in that it will pick up all waiting passengers from point A and transfer them to point B, but with one notable enhancement!
When the ferry arrives back at point A to pick up waiting passengers, it can be configured to wait just a little bit longer with the knowledge that new passengers will likely arrive. For example: if you know the trip between point A and point B is 10 minutes in duration, why not wait an extra 30 seconds at point A before departing? This may save you on roundtrips and improve the overall number of passengers that can be transported.
The configuration variables for artificial delay are binlog-group-commit-sync-delay (delay in microseconds) and binlog-group-commit-sync-no-delay-count (number of transactions to wait for before deciding to abort waiting).
Conclusion
In this example passengers are obviously transactions, and the ferry is an expensive fsync operation. It’s important to note that there is just one ferry in operation (a single set of ordered binary logs), so being able to tune this in 5.7 provides a nice level of advanced configuration.